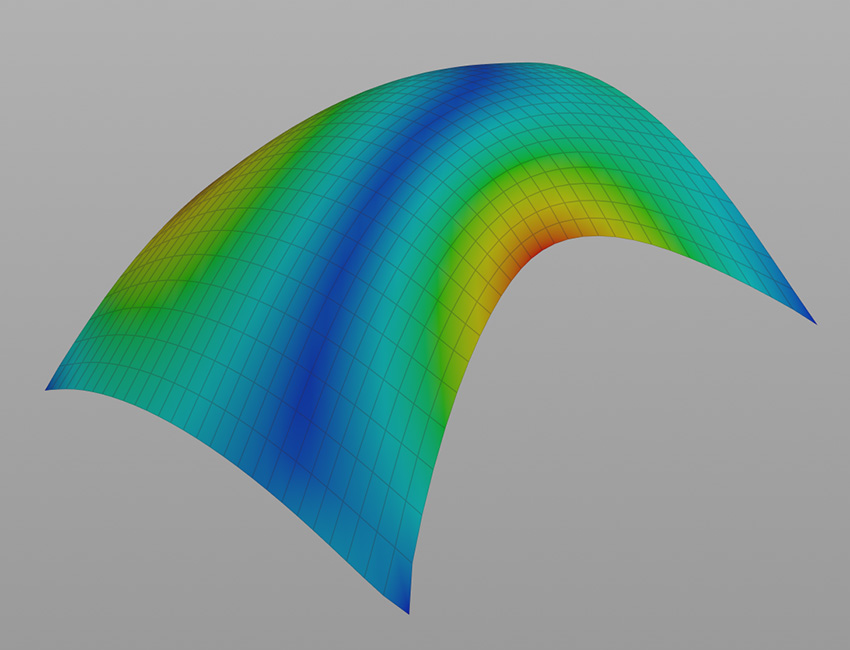
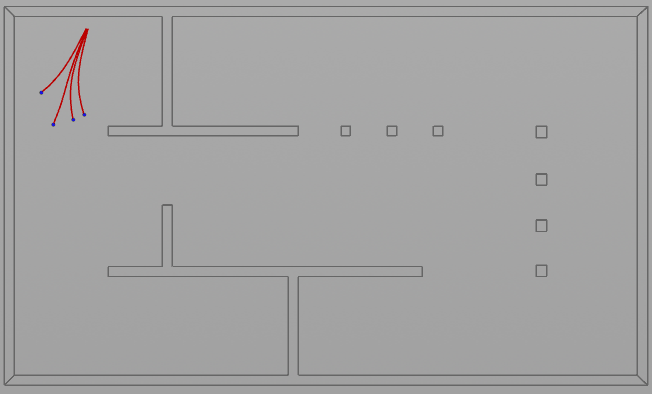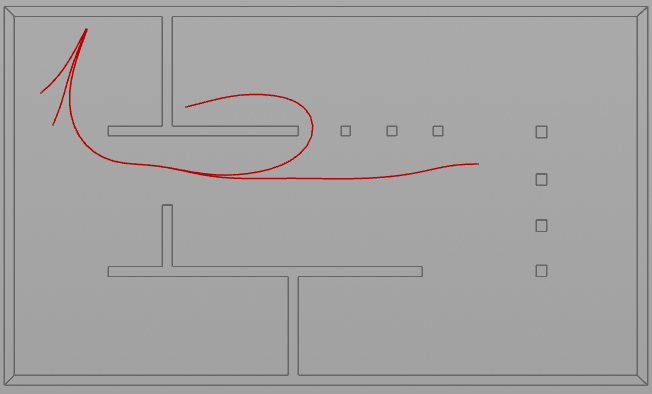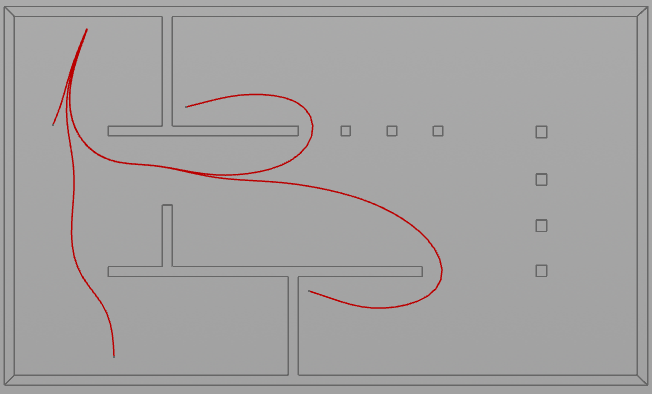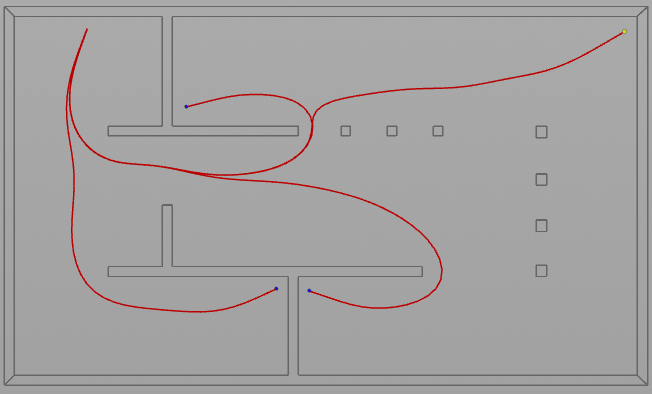
This is a follow-up to this blog post where I had written about various spatial metrics, but didn’t go into detail about how they are calculated and what they mean. This post is now the first of several to follow that will be about just these things.
So let’s start simple with the measure of similarity. But before that, some background on why we want to calculate it in the first place. Typically, an isovist describes local spatial properties. However, since (human) perception is strongly related to motion and locomotion, it makes sense to capture it in terms of relational or semi-global measures that account for motion to a certain degree; as an example, we might want to know the change in visible space relative to a change in position. One such metric is the measure of revelation. Revelation was introduced by Franz and Wiener and later further developed and refined by Dalton in his PhD thesis. It basically measures how much “new space” is revealed or lost as a person moves through space. It is calculated by taking the difference between the area of the current isovist and the mean area of adjacent (and visible) isovists. An alternative definition is to consider all isovists visible from the starting isovist, or more precisely, from the current position. Thus, the measure of revelation is conceptually somewhat related to the famous Laplacian (which I have written about many times on this blog in the past …).
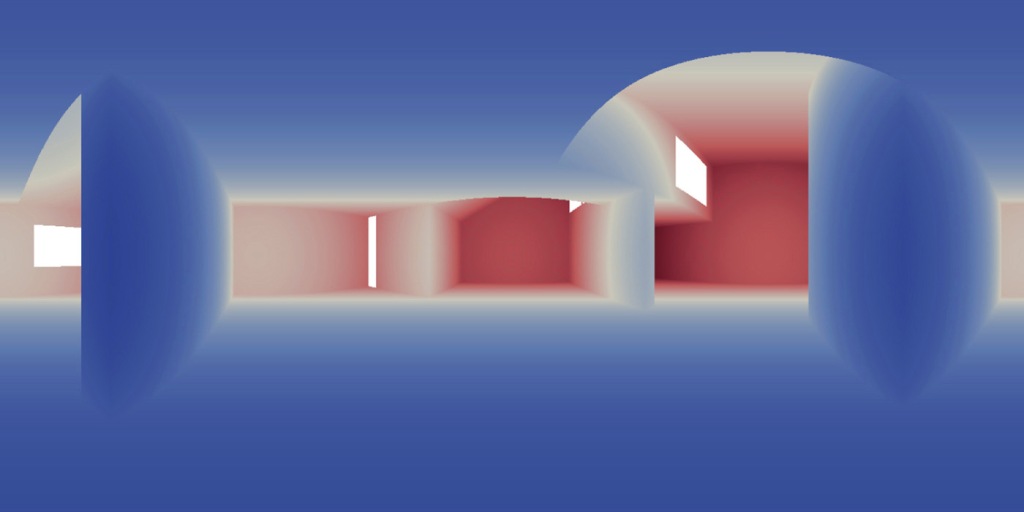
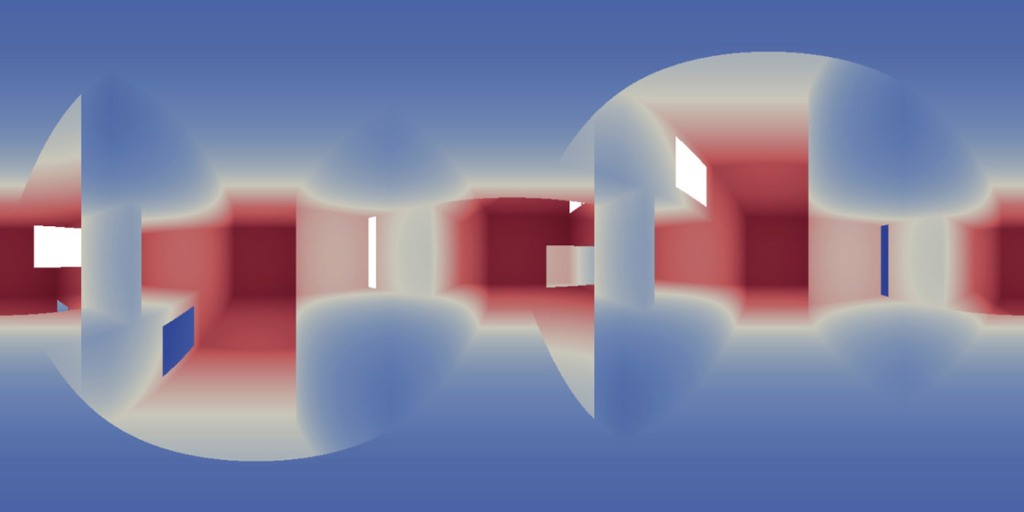
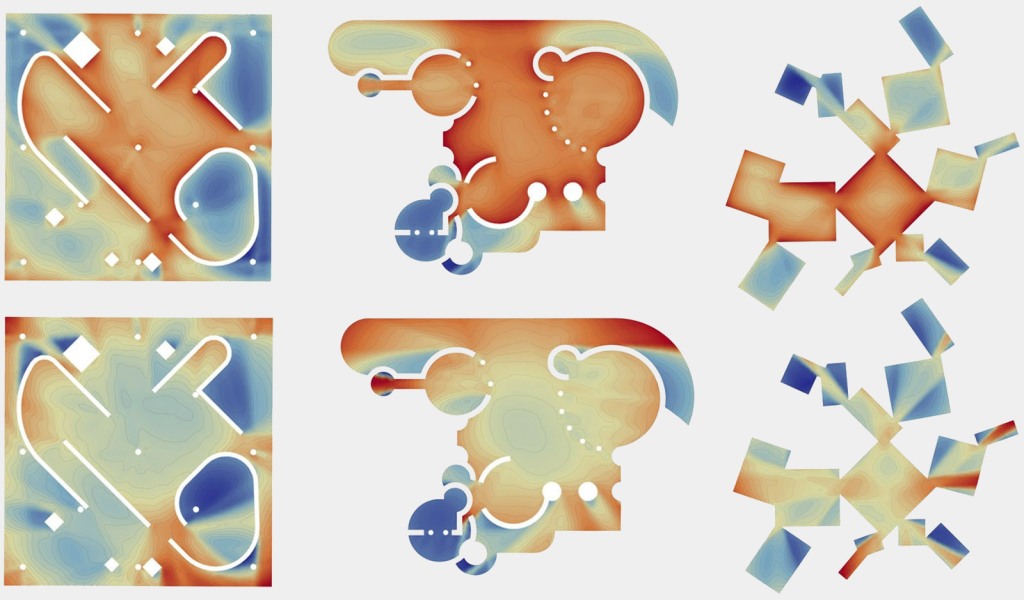
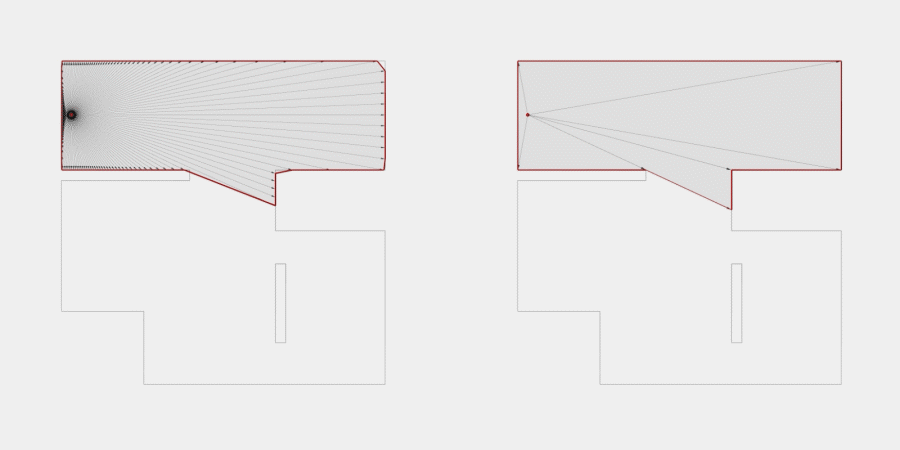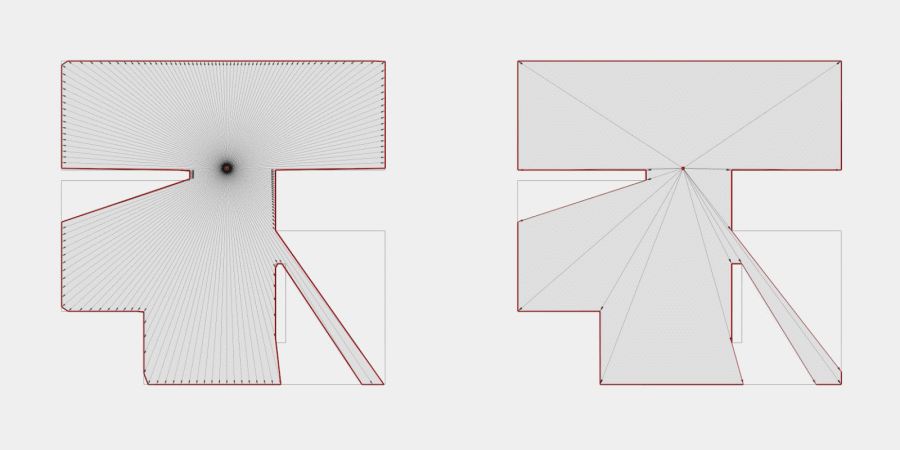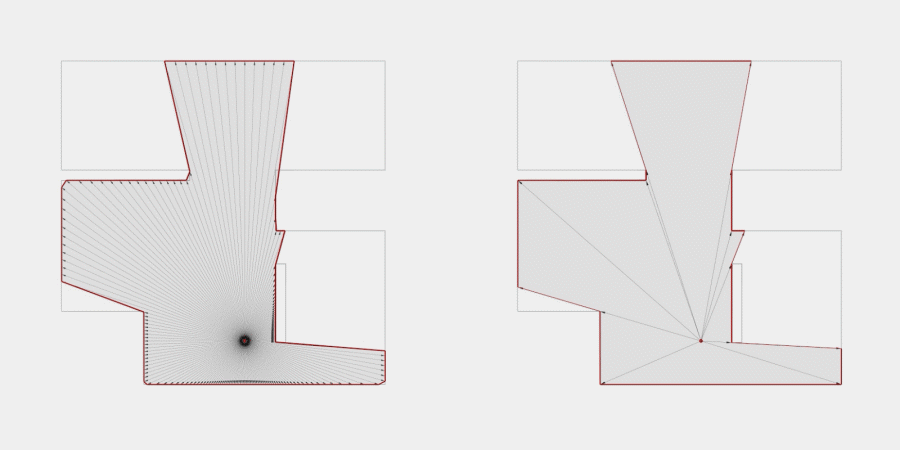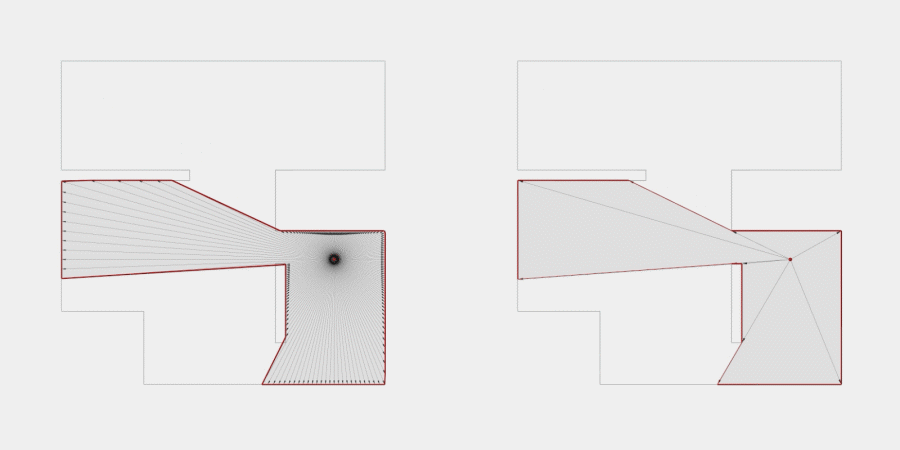
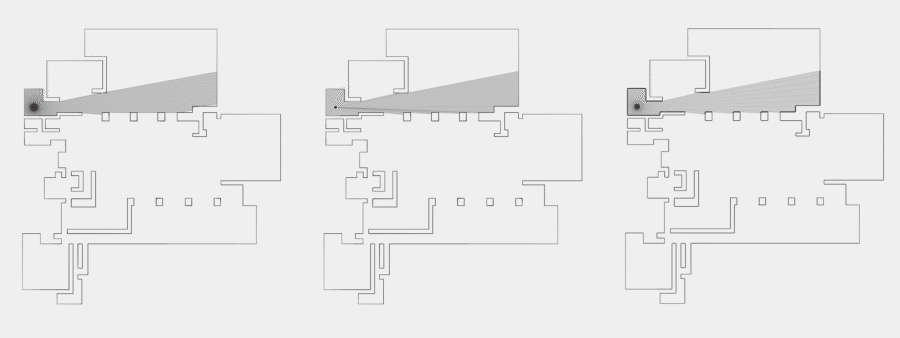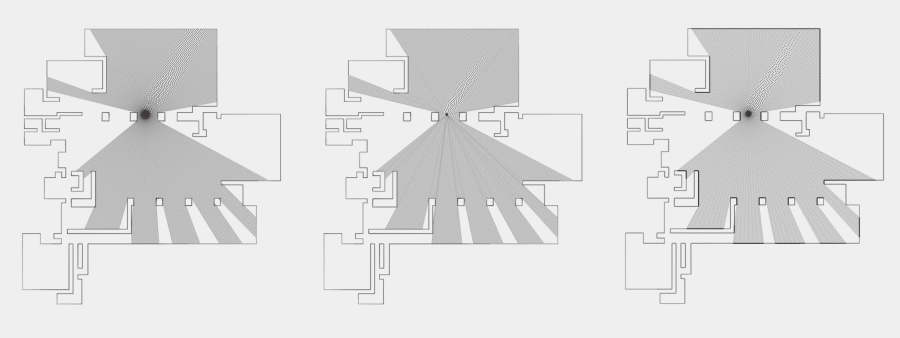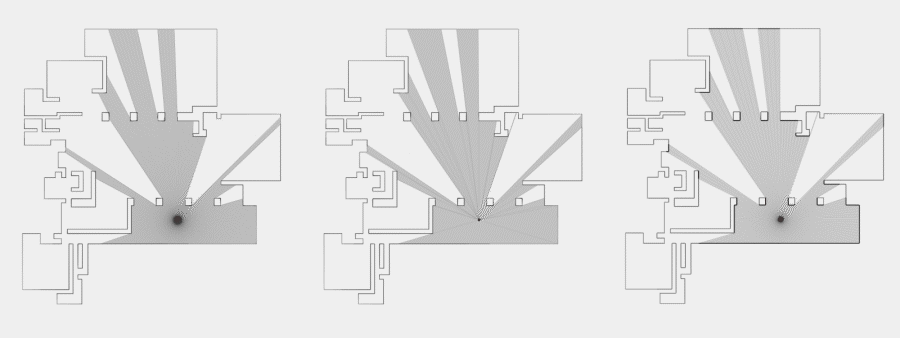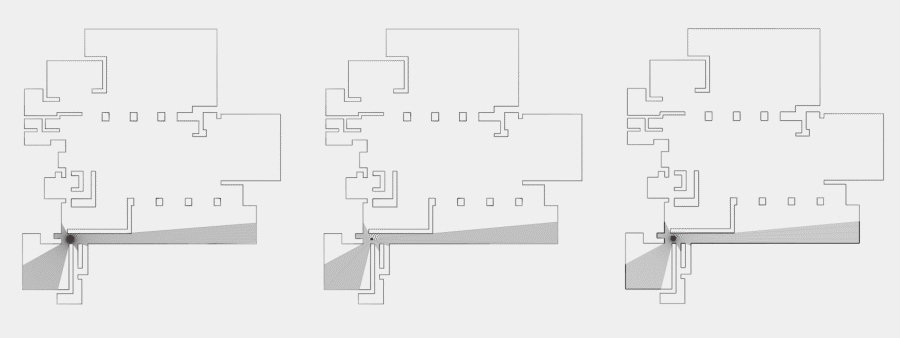
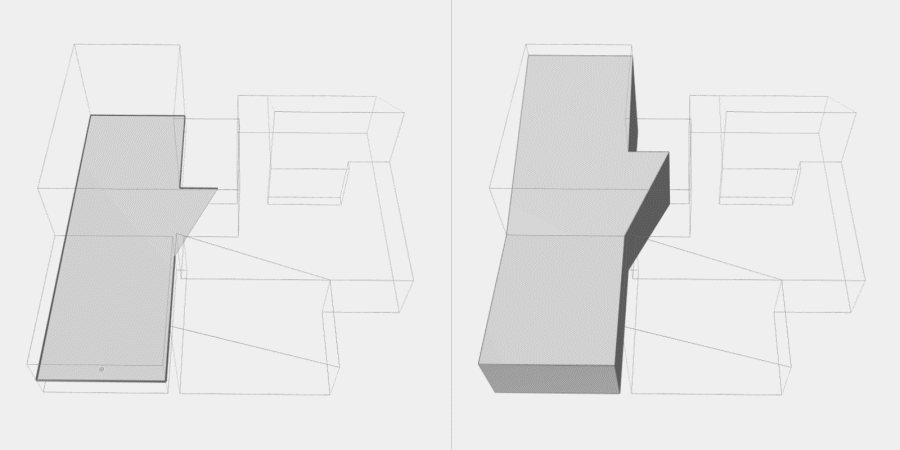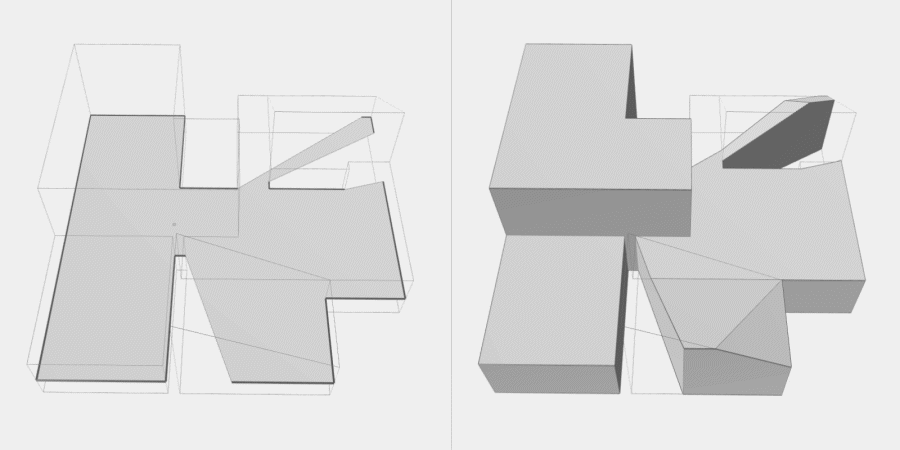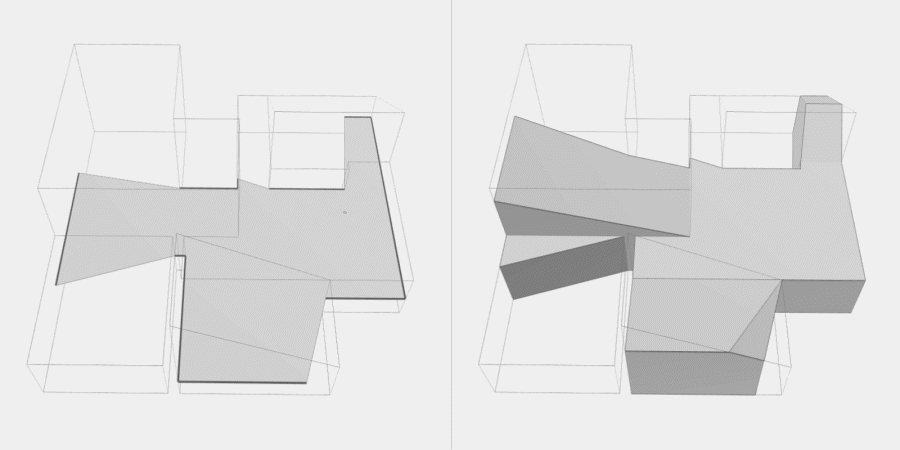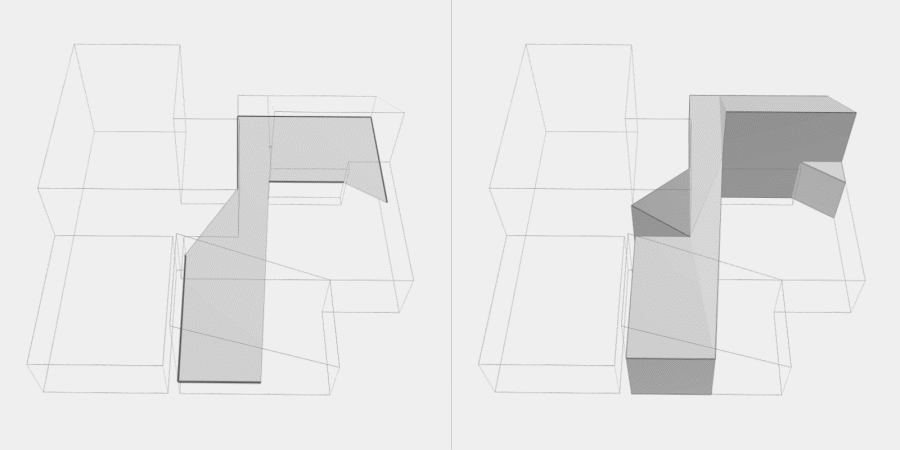
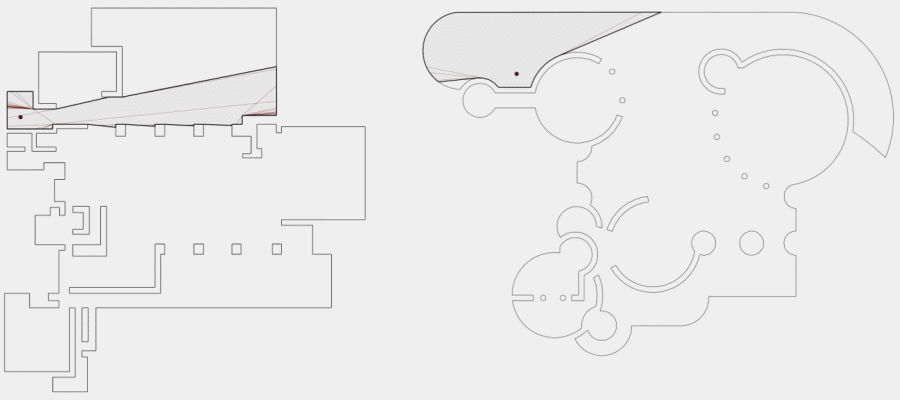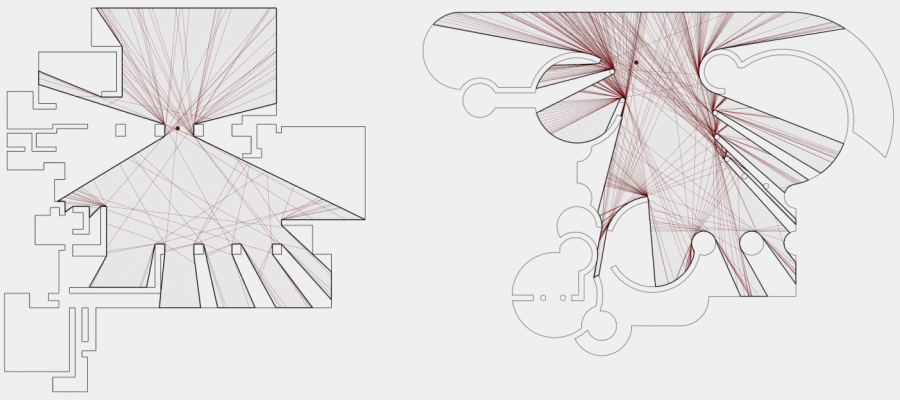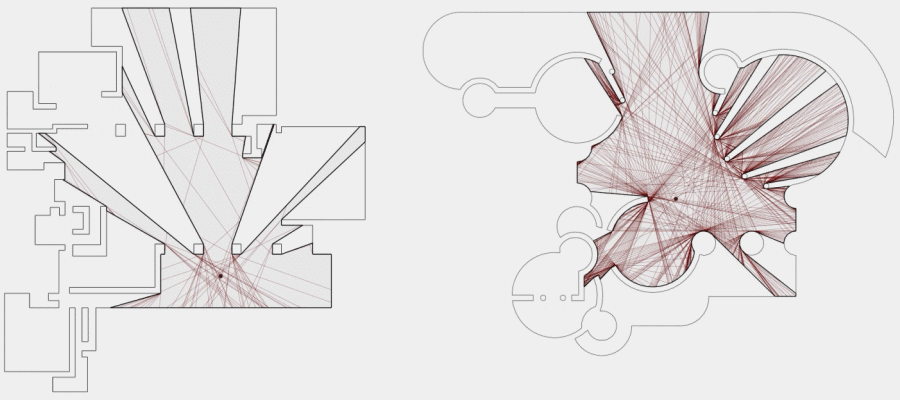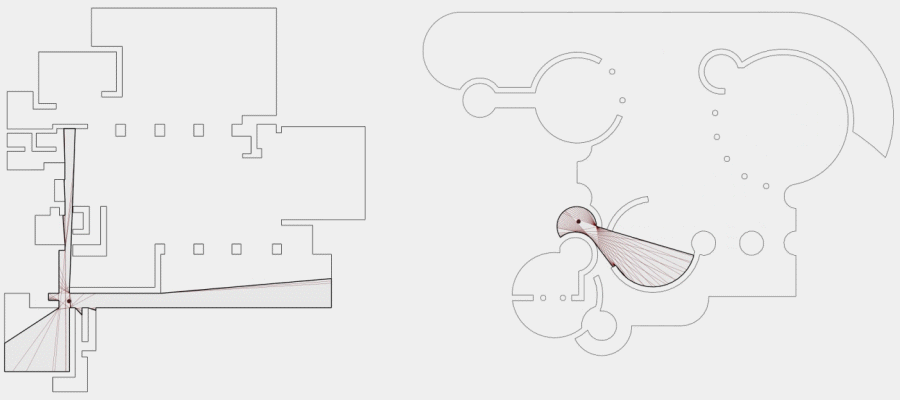
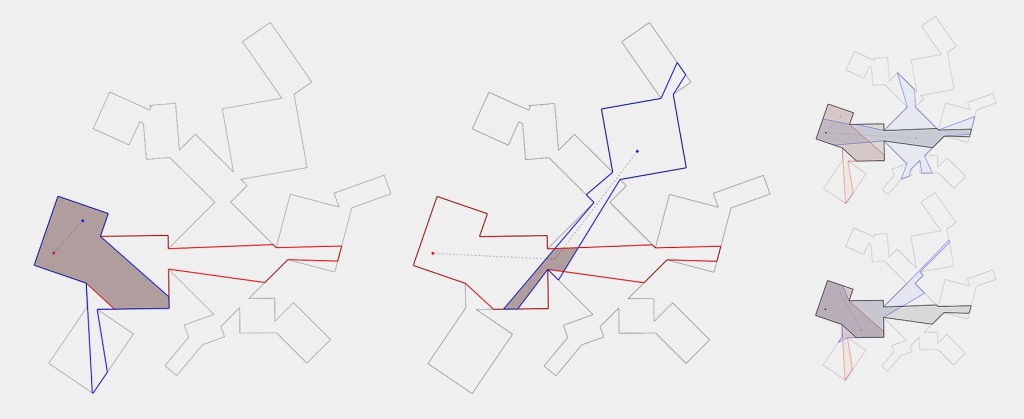
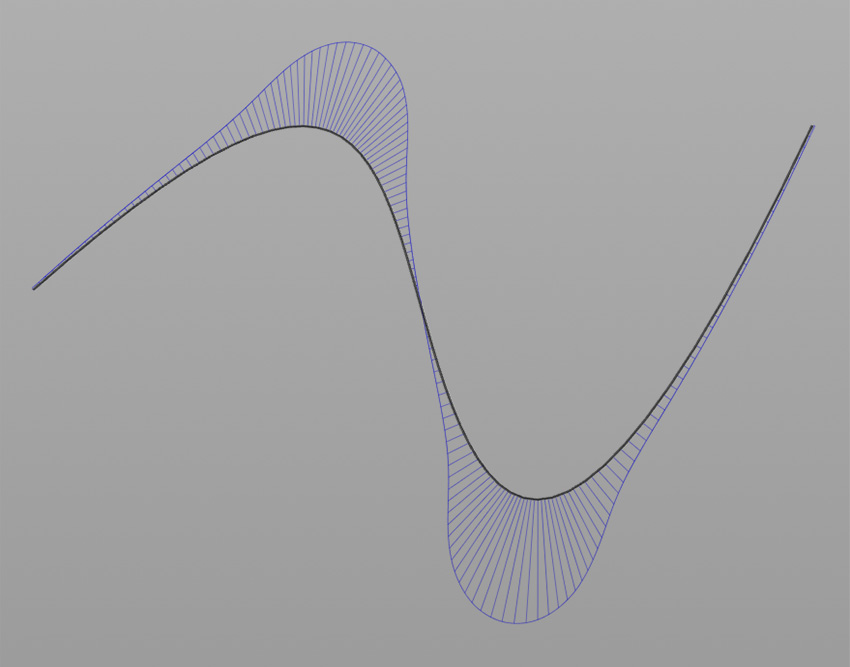
Now, to make it a little less abstract, let’s look at a simple example. An isovist is a geometric representation of visible space, relative to a particular position. Although geometrically it is a closed polygonal/polyhedral shape, not all boundary edges/polygons exist in reality. These “non-existent” boundary edges are simply extensions of the lines of sight and are called occluding edges. However, they do not match up with the surfaces of the “real” environment. Edges that match actual boundaries of the environment are called solid edges. The number and length, as well as their ratio, are very important properties as they capture various features of the environment from which the isovist is generated. Slightly simplified, we can say that the more occluding edges an isovist has and the longer these edges are, the more space will potentially be revealed when moving from one position to another. As various research studies have shown,this measure is closely related to the way people navigate and move around in spaces.
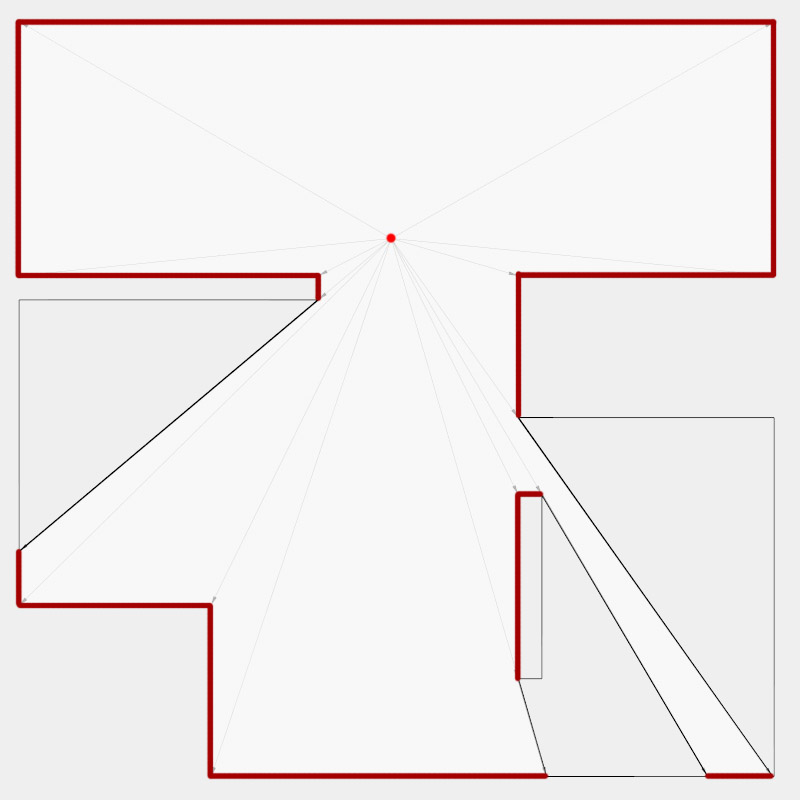
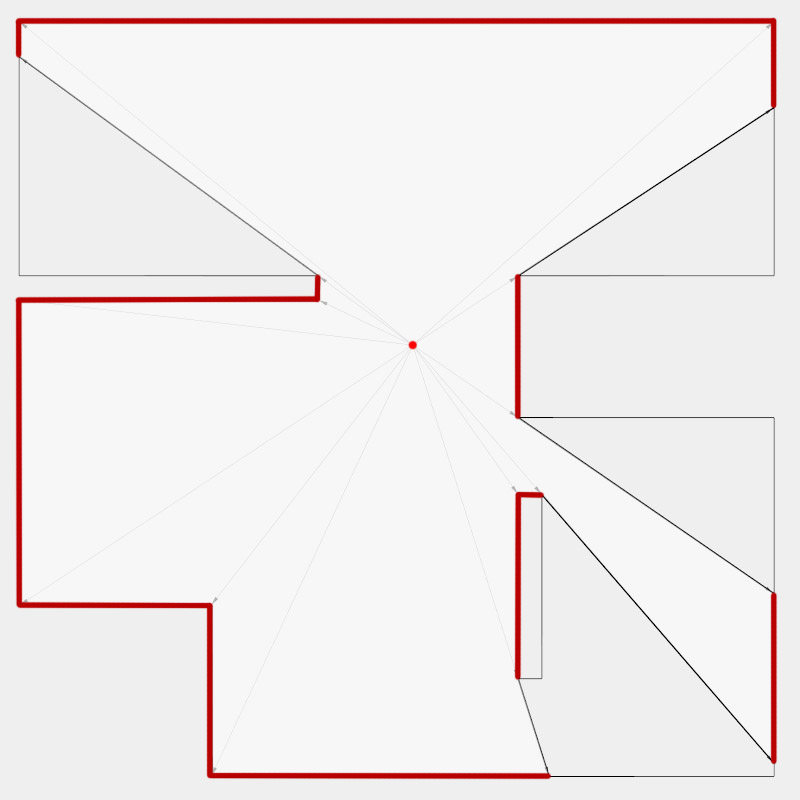
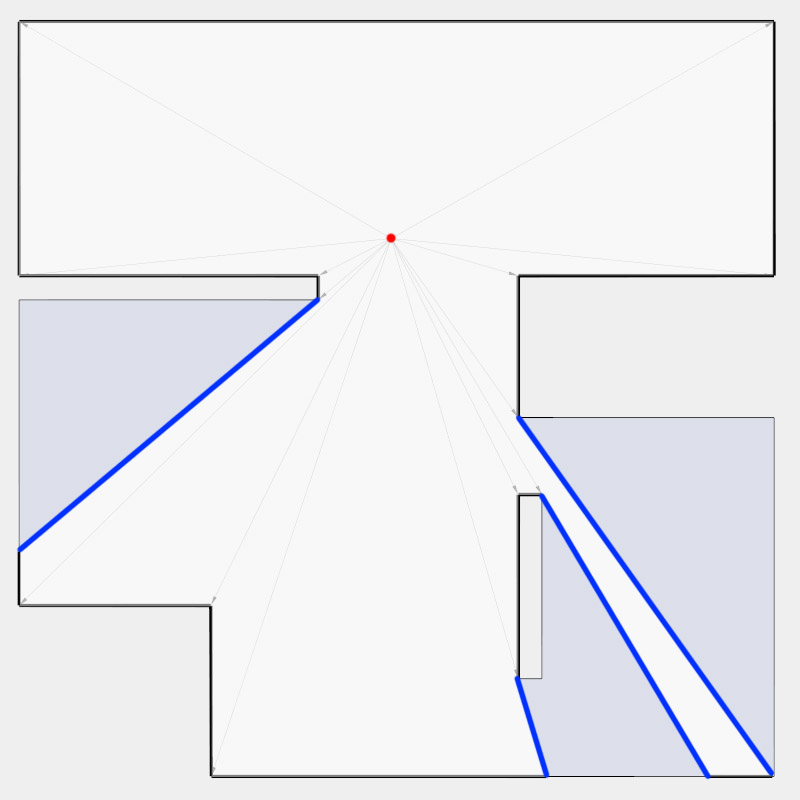
Two images on the right: Isovist polygons for two different locations. The thick red lines represent solid edges; the thinner black lines are occluding edges. Image on the right: The thick blue lines are occluding edges; the bluish color represents regions that could potentially be revealed by changing position.
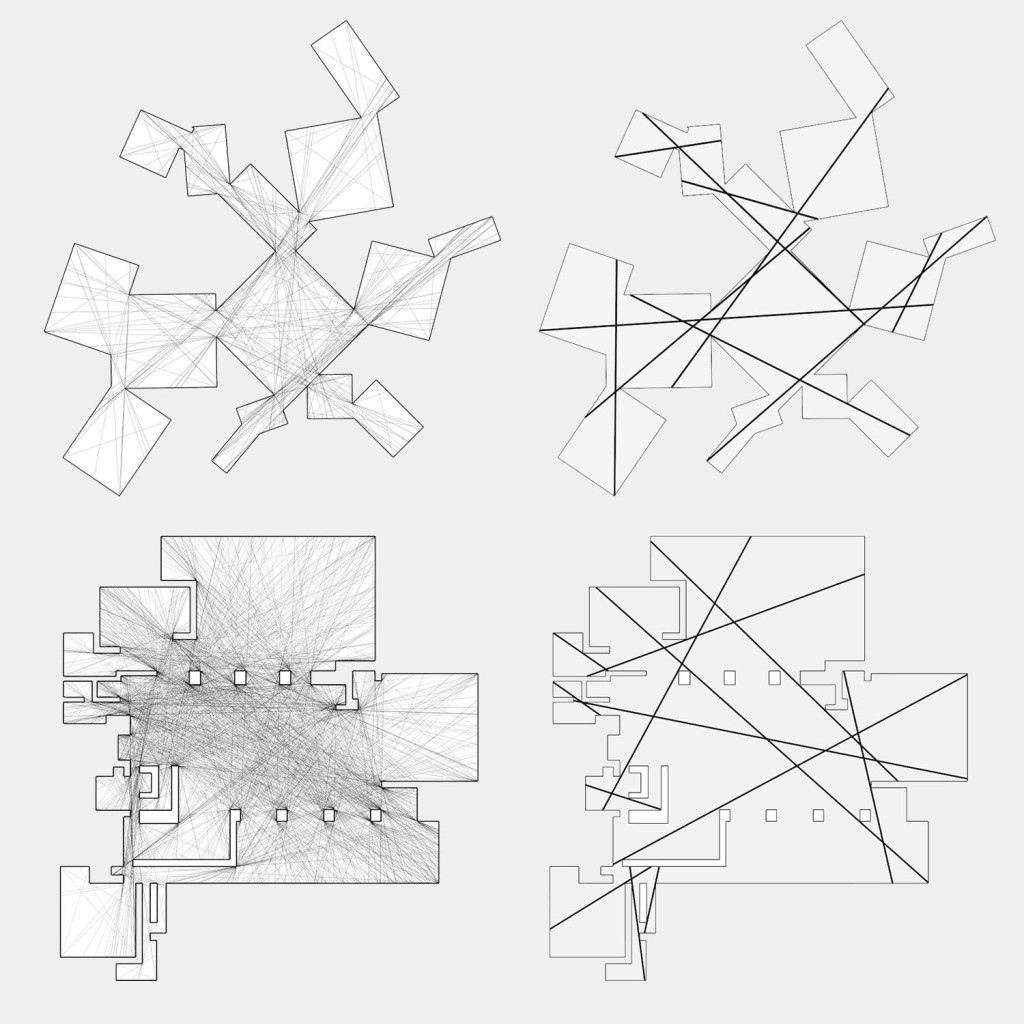
But now back to our similarity measure: Instead of considering only the change in area, we can also consider how much an isovist polygon/polyhedron changes geometrically in terms of its shape. And to do that, we need a way to quantify that change. The most obvious method, of course, is to sum the distances between each point of an isovist and the corresponding point of another isovist. After normalizing the total distance difference by the area of the isovists, we get what is certainly a valuable measure of how similar two shapes are. An even simpler way is to measure the difference between isovists by their radial distances. However, this method only works if the isovists have the same number and order of points, which might not be the case for two reasons: (1) we compute exact isovists (more on this here) or, (2) we compute the similarity measure only between solid edges of isovists. Fortunately, the similarity of shapes is an important property in computational geometry, and hence there are many papers by different authors providing different approaches to address this problem. The method I chose to implement is based on a paper by Belongie, Malik, and Puzicha and is a slightly modified version of their Shape Context Descriptor. This method is quite robust, fairly insensitive for noise, works in two and three dimensions, and since it’s essentially a statistical approach, it works with different numbers and orders of points. And last but not least, it can be easily implemented in OpenCL.
Basically it works as follows:
- Calculate the (euclidean) distance from each point to every other point of an isovist
- Calculate the mean distance and normalize all distances by this value (this results in distance values between 0.0 and 2.0)
- Calculate the angle to all points
- Shift the angles into the range of 0.0 – 2pi
- Compute a distance histogram based on a logarithmic scale between 0.0 and 2.0
- Count the number of distances in each bin
- Compute an angle histogram based on a linear scale between 0.0 and 2pi
- Count the number of angles in each bins
- Combine both histograms to get the local shape context descriptor
- Repeat the steps above for each point
- And finally compare two shapes by calculating the “difference” between the local descriptor from each point on one shape to every point on the other shape



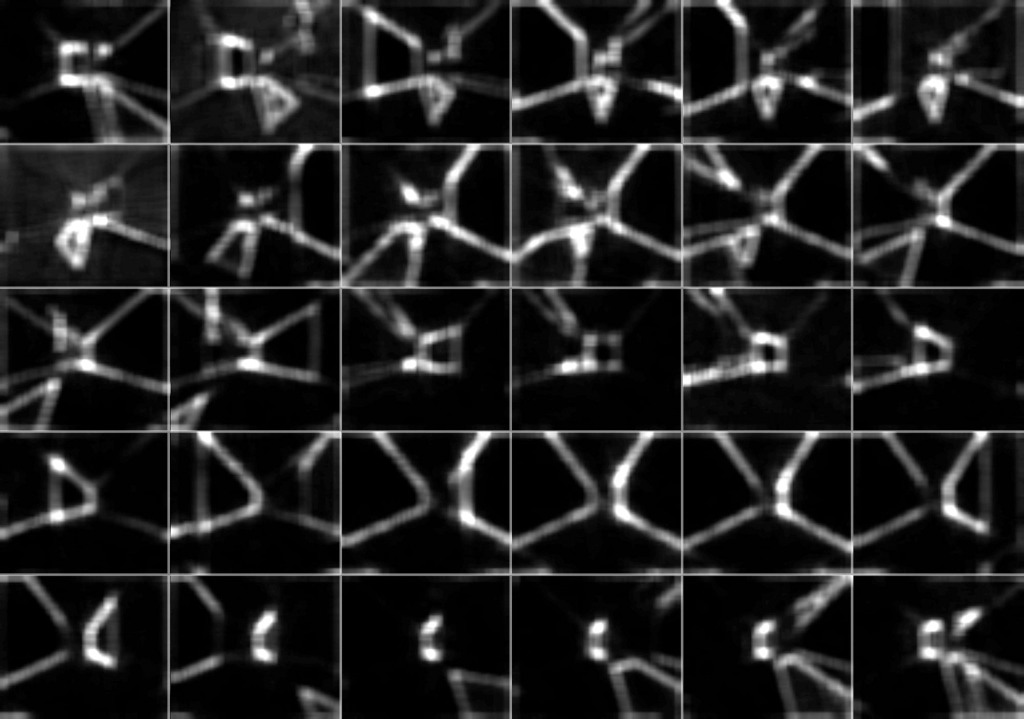
Distance histogram computation from left to right: (1) polygonal shape; (2) euclidean distance between all points; (3) distance matrix; (4) bin matrix for distance histogram (number of bins = 5)
In the same way that we computed the distance histogram, we can compute the angle histogram. Combining the two, we finally get the shape context descriptor for each point, which captures the local distribution of points relative to each point on the shape. However, instead of building it in matrix form, we store it as a flat array, so that it can be processed without problems by OpenCL.
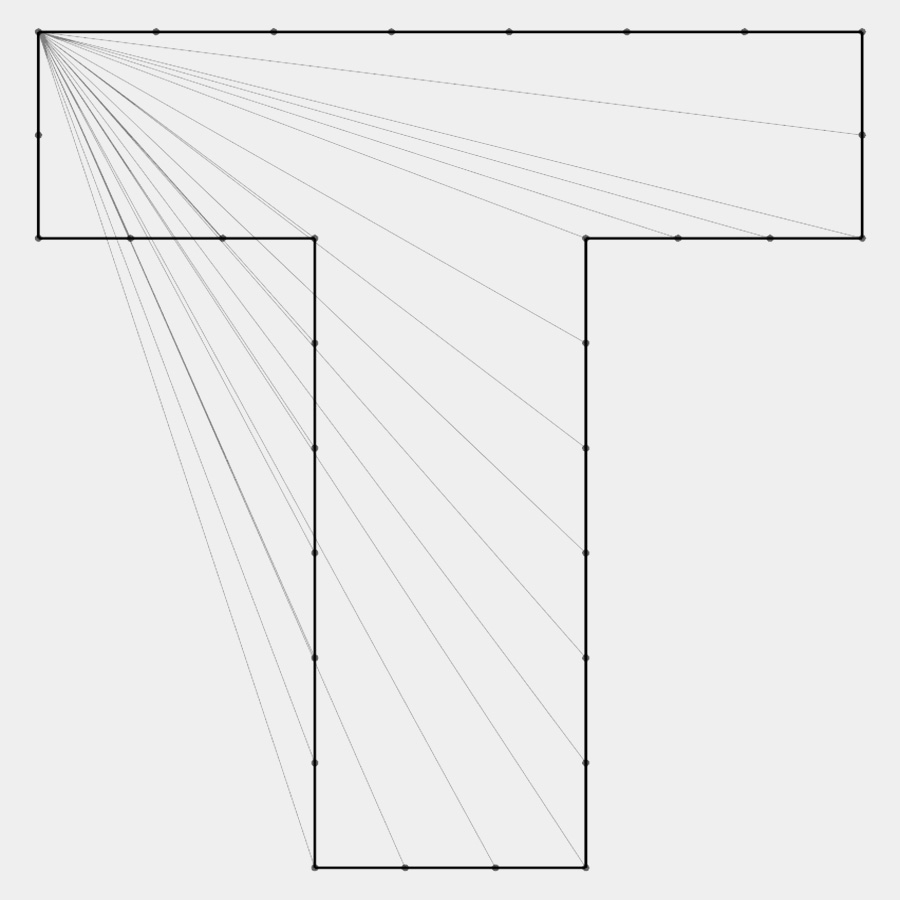

Right: Distance and angle from one point to every other point on the shape. Left: Shape context descriptor for one point.
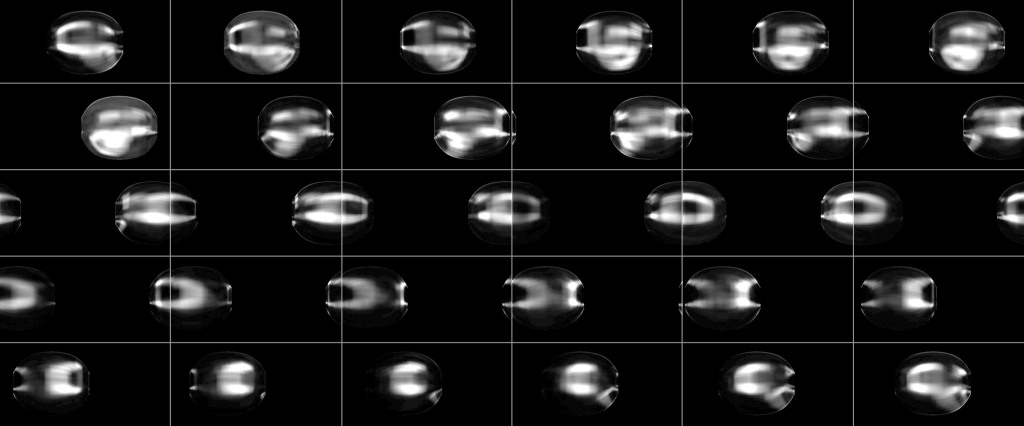
To calculate the similarity of shapes, we would normally calculate the difference between each point on one shape to each point on another shape. However, for performance reasons, I combine all local descriptors per point into one global descriptor per shape/isovist. Computing the similarity between thousands of shapes/isovists is therefore much faster, though less accurate. However, for my purpose, the result is still accurate enough.

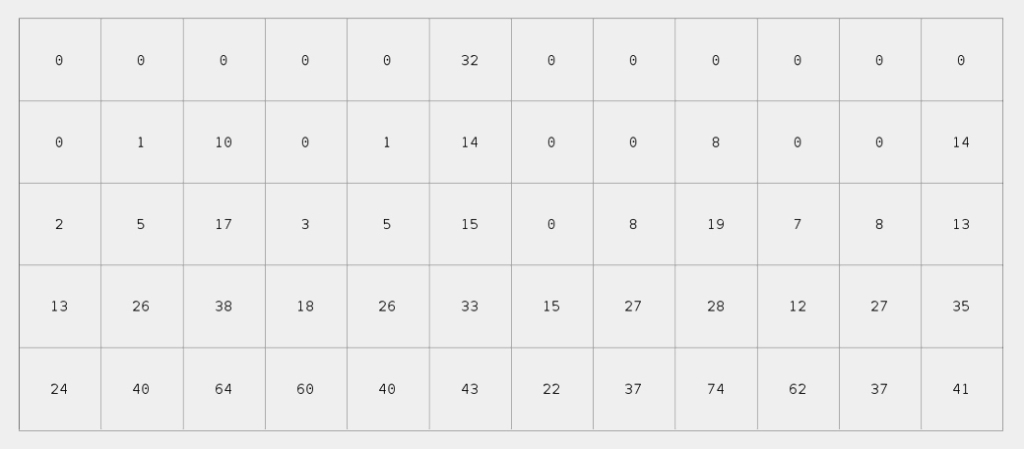

Combined per shape descriptor in matrix form (images at the top) and as flat array (image at the bottom). Number of bins for the distance histogram is 5, for the angle histogram 12.

Similarity measure between different shapes. Left: Shape; Middle: “Global” shape context descriptor; Right: Difference between descriptors (reference shape is T). Similarity from top to bottom: 1.0, 0.834, 0.723, 0.796, 0.854
For some related reading:
S. Belongie, J. Malik, J. Puzicha: Shape Matching and Object Recognition Using Shape Contexts.
S. Belongie, G. Mori, J. Malik: Matching with Shape Contexts.
Transactions on Pattern Analysis and Machine Intelligence, vol. 24, no. 24, 2002
J. Nowak, R. Eng, T. Matz, M. Waack, S. Persson, A. Sampathkumar, Z. Nikoloski: A network-based framework for shape analysis enables accurate characterization of leaf epidermal cells. Nature Communications, 2021.
R. Veltkamp: Shape Matching: Similarity Measures and Algorithms
G. Franz, J. Wiener: From space syntax to space semantics: a behaviourally and perceptually oriented methodology for the efficient description of the geometry and topology of environments. Environment and Planning B: Planning and Design 2008, volume 35, p. 574-592.
N. Dalton: Synergy, Intelligibility and Revelation in Neighbourhood Places. PhD Thesis, 2010